 Takeshi Kondo
Takeshi Kondo

Original article in Japanese: Kubernetes HPA External Metrics を利用した Scheduled-Scaling
Hi, I’m @chaspy from Site Reliability Engineering Team.
At Quipper, we use Kubernetes Horizontal Pod Autoscaler (HPA) to achieve pod auto-scaling.
The HPA can handle most ups and downs in the traffic. However, in general, it cannot deal with spike in traffic caused by unexpectedly high number of users accessing the platform at once. When the unexpected increase in CPU utilization happens, it would still take about 5 minutes to scale out the node even if HPA immediately increased the Desired Replicas.
Compared to the scaling mechanism based on the CPU utilization, Scheduled-Scaling can be defined as a method to schedule a fixed number of nodes/pods to be scaled at a specific time in the future. The simplest way to perform Scheduled-Scaling is to just change the minReplicas of the HPA at a specified time. This method may be efficient if the change is only made once or around the same time every day. However, if the spikes are expected at different times, it may be difficult to change the minReplicas every time.
In this article, I will explain a case study using Kubernetes HPA External Metrics to perform Scheduled-Scaling for traffic spike during regularly scheduled exams in the Philippines.
Background
In the Philippines, Quipper is already being used in the schools. Teachers and students have been using it for scheduled exams e.g., term end exams. The teachers register the questions for the examinations in the system before the exam.
One day while one of such scheduled exam was about to start, some students could not login into the portal at all. Schools and Customer Success teams got really confused because they suddenly started receiving complaints about students not being able to take the exam. After some investigation we found that this was due to a sudden traffic spike.
As a temporary solution, firstly, we avoided service downtime by setting the HPA minReplicas to a high enough value during daytime hours. However, this resulted in redundant server costs because we didn’t scale down the replicas during night time or during time when there was no traffic spike.

Description: The number of pods. It scales out up to 400 uniformly from 6:30 am to 7:30 pm.

Description: The number of Nodes also increases in proportion to the number of Pods.
To solve this problem, @naotori, Global Division Director, asked me if it would be possible to scale the server based on the starting time of the exam and the expected number of users in advance. Then, @bdesmero, Global Product Development VPoE, wrote a batch script to get the above data from our database. When we observed this data and the actual server metrics we found out that the server load correlates to the starting time of the exam and the expected number of users. We also found out the maximum number of users our current architecture could handle from the metrics.
Therefore, to optimize the number of pods/nodes which were being scaled out excessively, we decided to use the data obtained by @bdesmero as external metrics for HPA and used it together with CPU auto-scaling to achieve Scheduled-Scaling safely.
Mechanism: HPA External Metrics and Datadog Custom Metrics Server
HPA is widely known for auto-scaling based on CPU, but autoscaling based on External Metrics is available since apiversion auto-scaling/v2beta1. Since Quipper uses Datadog, I decided to use Datadog metrics as External Metrics.
So how do you autoscale by using the Datadog metric? HPA Controller is designed to get metrics from Kubernetes metrics api(metrics.k8s.io, custom.metrics.k8s.io, external.metrics.k8s.io).
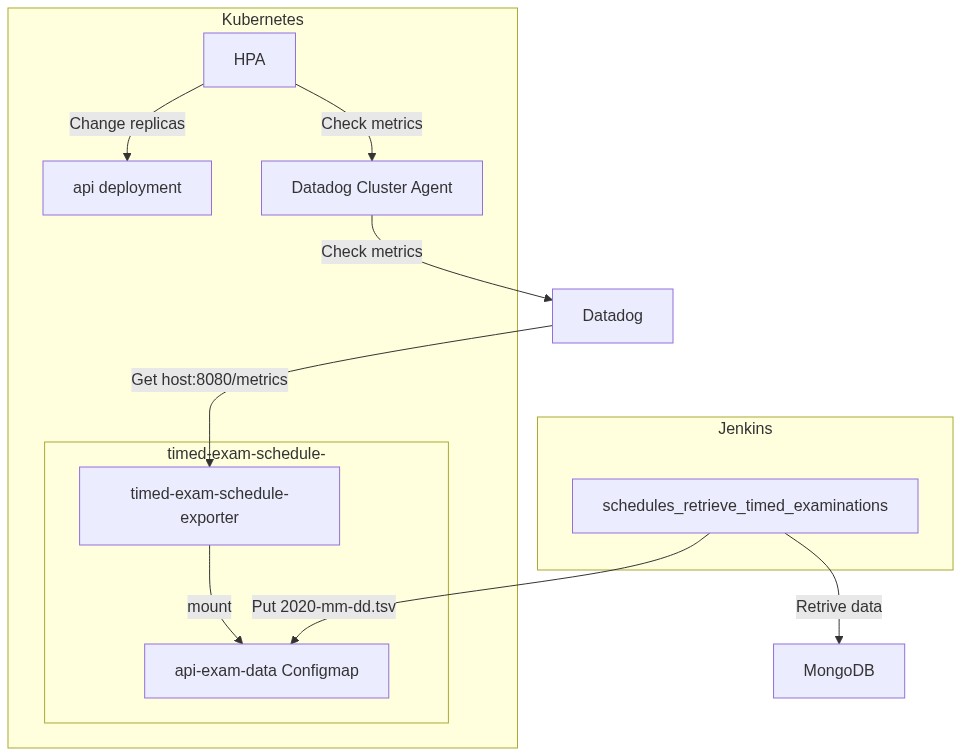
Setting it up in accordance with the documentation of the Datadog Custom Metrics Server, the API Service is added. By registering the API Service, it is registered in the Aggregation Layer of the Kubernetes API, and HPA can retrieve metrics from Datadog’s Metrics Server via the Kubernetes API. Here is a diagram.

Furthermore, if you want to use Datadog’s metrics query, register CRD called datadogmetric.
First, the Datadog cluster-agent checks if the HPA spec.metrics field is external, parses the metric name such as datadogmetric@<namespace>:<name>, and then sets the HPA Reference field.
First, the Datadog cluster-agent checks if the HPA spec.metrics field is external, parses the metric name such as datadogmetric@<namespace>:<name>, and then sets the HPA Reference field.
The HPA then queries the metrics server for references, and the cluster-agent receives it and returns the query retrieved from Datadog. As a side note, the Controller seems to save the query retrieved as a Local Store and sync it to the DatadogMetric resource in the Reconcile Loop rather than querying Datadog each time.
Architecture
Next, I will explain the architecture of using the Datadog metrics server and HPA to achieve Scheduled-Scaling.
Fetch data from our database and save it as a ConfigMap
See the area around schedules_retrive_timed_examinations at the bottom right (check the diagram above). @bdesmero created this part. schedules_retrive_timed_examinations gets the starting time of the exam and the corresponding number of students from our database and saves it as a TSV file. The TSV file looks like this:
12:00 229
12:15 54
12:45 67
13:00 3684
13:15 91
13:30 4821
13:45 37
14:00 138
We divided the work between @bdesmero (as the web developer) and me (as the SRE). The dependency on Jenkins and the use of ConfigMap is a drawback that increases the number of points of failure. Still, I think it was a reasonable choice for the shortest possible time and cooperation.
Export the read data from TSV in Prometheus format
Next, let’s take a look at the timed-exam-schedule-exporter component on the bottom left. It is written in Go and runs as a Kubernetes Deployment.
This component does the following:
- Mount the ConfigMap
- Read the file in an infinite loop
- Compare with the current time
- Export the corresponding number of users in Prometheus format
The key point is to export the value 15 minutes after the current time because we want pods/nodes to start scaling out 15 minutes before users access it, given the time it takes to scale.
Let’s take a look at the code(it’s not that long, around 180 lines).
package main
import (
"encoding/csv"
"errors"
"fmt"
"io"
"log"
"net/http"
"os"
"strconv"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
//nolint:gochecknoglobals
desiredReplicas = prometheus.NewGauge(prometheus.GaugeOpts{
Namespace: "timed_exam",
Subsystem: "scheduled_scaling",
Name: "desired_replicas",
Help: "Number of desired replicas for timed exam",
})
)
func main() {
const interval = 10
prometheus.MustRegister(desiredReplicas)
http.Handle("/metrics", promhttp.Handler())
go func() {
ticker := time.NewTicker(interval * time.Second)
// register metrics as background
for range ticker.C {
err := snapshot()
if err != nil {
log.Fatal(err)
}
}
}()
log.Fatal(http.ListenAndServe(":8080", nil))
}
func snapshot() error {
const timeDifferencesToJapan = +9 * 60 * 60
tz := time.FixedZone("JST", timeDifferencesToJapan)
t := time.Now().In(tz)
today := t.Format("2006-01-02")
// Configmap is mounted
filename := "/etc/config/" + today + ".tsv"
file, err := os.Open(filename)
if err != nil {
return fmt.Errorf("failed to open file: %w", err)
}
defer file.Close()
currentUsers, err := getCurrentUsers(t, tz, file)
if err != nil {
return fmt.Errorf("failed to get the current number of users: %w", err)
}
desiredReplicas.Set(currentUsers)
return nil
}
func getCurrentUsers(now time.Time, tz *time.Location, file io.Reader) (float64, error) {
const metricTimeDifference = +15
// read input file
reader := csv.NewReader(file)
reader.Comma = '\t'
// line[0] is time. i.e. "13:00"
// line[1] is users. i.e. "350"
var previousNumberOfUsers float64 // A variable for storing the value of the previous loop
var index int64
for {
index++
parsedTSVLine, err := parseLine(reader, now, tz)
if errors.Is(err, io.EOF) {
return previousNumberOfUsers, nil
}
if err != nil {
return 0, fmt.Errorf("failed to parse a line (line: %d): %w", index, err)
}
// Example:
// line[0] line[1]
// 17:00 4
// 17:15 10
//
// Loop compares the current time with the time on line[0],
// and if the current time is later than the current time,
// the previous line[1] is used as gauge.
//
// To prepare the pods and nodes "metricTimeDifference" minutes in advance,
// expose the value "metricTimeDifference" minutes ahead of the current value.
// In the above example, it will expose 10 at 17:00.
if parsedTSVLine.time.After(now.Add(metricTimeDifference * time.Minute)) {
// If the time of the first line is earlier than the time of the first line,
// expose the value of the first line.
if previousNumberOfUsers == 0 {
return parsedTSVLine.numberOfUsers, nil
} else {
return previousNumberOfUsers, nil
}
}
previousNumberOfUsers = parsedTSVLine.numberOfUsers
}
}
type tsvLine struct {
time time.Time
numberOfUsers float64
}
func parseLine(reader *csv.Reader, now time.Time, tz *time.Location) (tsvLine, error) {
line, err := readLineOfTSV(reader)
if err != nil {
return tsvLine{}, fmt.Errorf("failed to read a line from TSV: %w", err)
}
parsedTime, err := parseTime(line[0], now, tz)
if err != nil {
return tsvLine{}, fmt.Errorf("failed to parse time from string to time: %s: %w", line[1], err)
}
parsedNumberOfUsers, err := strconv.ParseFloat(line[1], 64)
if err != nil {
return tsvLine{}, fmt.Errorf("the TSV file is invalid. The value of second column must be float: %s: %w", line[1], err)
}
return tsvLine{
time: parsedTime,
numberOfUsers: parsedNumberOfUsers,
}, nil
}
func parseTime(inputTime string, t time.Time, tz *time.Location) (time.Time, error) {
const layout = "15:04"
// parse "13:00" -> 2020-11-05 13:00:00 +0900 JST
startTime, err := time.ParseInLocation(layout, inputTime, tz)
if err != nil {
return time.Time{}, fmt.Errorf("failed to parse a time string %s (layout: %s): %w", inputTime, layout, err)
}
parsedTime := time.Date(
t.Year(), t.Month(), t.Day(),
startTime.Hour(), startTime.Minute(), 0, 0, tz)
return parsedTime, nil
}
func readLineOfTSV(reader *csv.Reader) ([]string, error) {
const columnNum = 2
line, err := reader.Read()
if errors.Is(err, io.EOF) {
return line, fmt.Errorf("end of file: %w", err)
}
if err != nil {
return line, fmt.Errorf("loading error: %w", err)
}
// Check if the input tsv file is valid
if len(line) != columnNum {
return line, fmt.Errorf("the input tsv column is invalid. expected: %d actual: %d", columnNum, len(line))
}
return line, nil
}
The main() and the snapshot() functions are the essential parts to this design pattern.
In main(), we do some background processing using a ticker and listen on HTTP port 8080.
In snapshot(), we read the file, get the values we need, and set them as gauge metrics in desiredReplicas.Set(currentUsers).
The rest of the code is to read and parse lines. Basically, in the Prometheus Go client library, the timestamp is set to the current time. In Datadog, timestamps cannot be set more than 10 minutes in the future or more than 1 hour in the past, so we export the value after 15 minutes to the current time.
Here is an example of getting the exported metrics.
# in another window
# kubectl port-forward timed-exam-schedule-exporter-775fcc7c5b-qg6q6 8080:8080 -n timed-exam-schedule-exporter
$ curl -s localhost:8080/metrics | grep timed_exam_scheduled_scali
ng_desired_replicas
# HELP timed_exam_scheduled_scaling_desired_replicas Number of desired replicas for timed exam
# TYPE timed_exam_scheduled_scaling_desired_replicas gauge
TYPE timed_exam_scheduled_scaling_desired_replicas gauge
Get datadog-agent to scrape the exported metrics.
We use Datadog Kubernetes Integration Autodiscovery, which looks at the Pod’s annotation and fetches the metrics for us.
Here is the deployment manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: timed-exam-schedule-exporter
namespace: timed-exam-schedule-exporter
labels:
name: timed-exam-schedule-exporter
spec:
replicas: 3
selector:
matchLabels:
app: timed-exam-schedule-exporter
template:
metadata:
labels:
app: timed-exam-schedule-exporter
annotations:
ad.datadoghq.com/timed-exam-schedule-exporter.check_names: |
["prometheus"]
ad.datadoghq.com/timed-exam-schedule-exporter.init_configs: |
[{}]
ad.datadoghq.com/timed-exam-schedule-exporter.instances: |
[
{
"prometheus_url": "http://%%host%%:8080/metrics",
"namespace": "timed_exam",
"metrics": ["*"]
}
]
spec:
containers:
- image: <aws-account-id>.dkr.ecr.<region-name>.amazonaws.com/timed-exam-schedule-exporter:<commit hash>
name: timed-exam-schedule-exporter
ports:
- name: http
containerPort: 8080
livenessProbe:
initialDelaySeconds: 1
httpGet:
path: /metrics
port: 8080
resources:
limits:
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- mountPath: /etc/config
name: config-volume
volumes:
- configMap:
defaultMode: 420
name: api-exam-data
name: config-volume
Use Datadog query to scale in HPA
Finally, take a look at the upper left part of the diagram. It’s probably easier to understand if you look at the manifest.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: api
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api
minReplicas: 40
maxReplicas: 1000
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60 # want 570 mcore of cpu usage. 570 / 950(requests) = 0.6
- type: External
external:
metric:
name: datadogmetric@production:timed-exam
target:
type: AverageValue
averageValue: 1
The “type: External” part is the new part that we added to our existing HPA. Note that HPA allows us to specify multiple metrics, and it uses the higher value once it has been calculated. Thanks to this mechanism, it is possible to achieve a combination of scaling by different metrics at specific times while we do CPU scaling.
Here is the DatadogMetric referred.
apiVersion: datadoghq.com/v1alpha1
kind: DatadogMetric
metadata:
name: timed-exam
spec:
# throughput: 10 = 500 / 5000. 500 pods accept 5000 users.
# ref: https://github.com/quipper/xxxxxxx/issues/xxxxx
query: ceil(max:timed_exam.timed_exam_scheduled_scaling_desired_replicas{environment:production}/10)
Datadog custom metrics timed_exam.timed_exam_scheduled_scaling_expected_users represents the number of users written in the TSV file. Datadog query calculates how many pods are required per user.
By using the Datadog query, I was able to reduce the amount of code to write.
How to apply
After having confirmed the operation in Staging, I applied the following steps in Production:
Deploy ConfigMap and timed-exam-schedule-exporter to Production, and send metrics to Datadog. Apply Datadog Metrics and test HPA to confirm if the HPA works as expected. Update the HPA with the production application. The minReplicas should be large at this time. Gradually lower the value of minReplicas while we observe the situation.
Since this is a configuration change related to production scaling, and there are many integrated parts, I had to apply it carefully.
Note that even if you only apply DatadogMetric, HPA Controller does not retrieve the metric unless HPA references the DatadogMetric. That’s because the cluster-agent executes a DatadogMetric Query and updates the status only when HPA Controller retrieves the metric. Therefore, we used a dummy application and HPA for the verification at step 2.
Once I knew that the Datadog custom metric and HPA settings were all in place, to test the setup, I set minReplicas to a high value; then, I gradually decreased the replicas while keeping an eye on the actual TSV file to make sure the number of replicas changed based on the data in the TSV file. I was able to confirm the replicas scaled out properly.
FAQ
What happens if the TSV file is invalid?
The timed-exam-schedule-exporter exposes 0 value. In which case, it scales by the CPU.
What happens if the communication with Datadog fails?
Datadog cluster-agent sets Invalid status to DatadogMetric Custom Resource, and the result of the HPA external metric calculation shows unknown. In this case, It is scaled by CPU.
What happens if the timed-exam-schedule-exporter goes down?
The metrics are not exposed to Datadog so the metric will result in No Data in Datadog. The metrics will be scaled by CPU as above.
In both cases, thanks to HPA’s behavior regarding multiple metrics, CPU scaling kicks in even if something goes wrong with the external metrics.
Result
The number of pods and nodes we have got so far:

The number of pods scale out up to 400 uniformly from 6:30 am to 7:30 pm.

The number of Nodes also increases in proportion to the number of Pods.
And this is the number of Pods and custom metrics one week after we started using Scheduled-Scaling :

The yellow line is the metric registered with DatadogMetric Custom Resource, and the purple line is the HPA Desired Replicas.
How amazing it is! When there’s no traffic spike, the scaling is executed by CPU. On the other hand, when many users are expected to use the platform, scaling is executed by the External Metrics.
The number of Nodes is also lower than before. The decreasing of the area graph indicates that we reduced costs. The daily usage cost has gone down to $145 from $250, and estimated cost reduction is about $3150 monthly.

The purple line is the number of Nodes before we started using Scheduled-Scaling. The blue line is the number of Nodes after we started using Scheduled-Scaling.
We achieved flexible scaling based on the domain data of the number of users in scheduled exam. Furthermore we were able to eliminate human intervention, and reduce the redundant infrastructure cost. That’s great!
Conclusion
In this article, I explained how to send the number of users in Datadog custom metrics and then the way to scale them as External Metrics with HPA. The multiple metrics of the HPA enabled us to achieve Scheduled-Scaling safely while using it together with the CPU-based scaling. As a result, we were able to ensure both of resource efficiency and reliability.
This case study has led us to adopt Datadog metrics as an external metric for HPA. We have confirmed cases where CPU scaling does not work well for some services using a messaging/queue system like Google Cloud Pub/Sub. I think that auto-scaling by queue length metric in Datadog might help scale those services properly.
Besides, I think this is a great example of problem solving through communication among different teams with different roles and responsibilities, including SRE, Web Developer, and Business Developer. We SREs may know how to use Kubernetes HPA and Datadog, but we don’t know the details of the database and application features, such as the domain knowledge of the service. I think this is an excellent example of a problem solving by close communication. We were able to share the problems and face them together. That led us to the success!
Quipper is looking for people who want to Bring the Best Education to Every Corner of the World. SRE Team is also hiring.